ユートピアの暗号に挑む2
今回は具体的な言語の考察へと進んでいく。
まずは、前記事で述べた通り「日本語、英語、フランス語、エスペラント語、サンスクリット語」の5言語に候補を絞る。日本語、英語以外の言語については、筆者も初めて学ぶが、とにかく「暗号を解く」という観点に絞って情報を集めることにする。
0.手掛かりの整理
まず、暗号文の手掛かりを整理しておく。
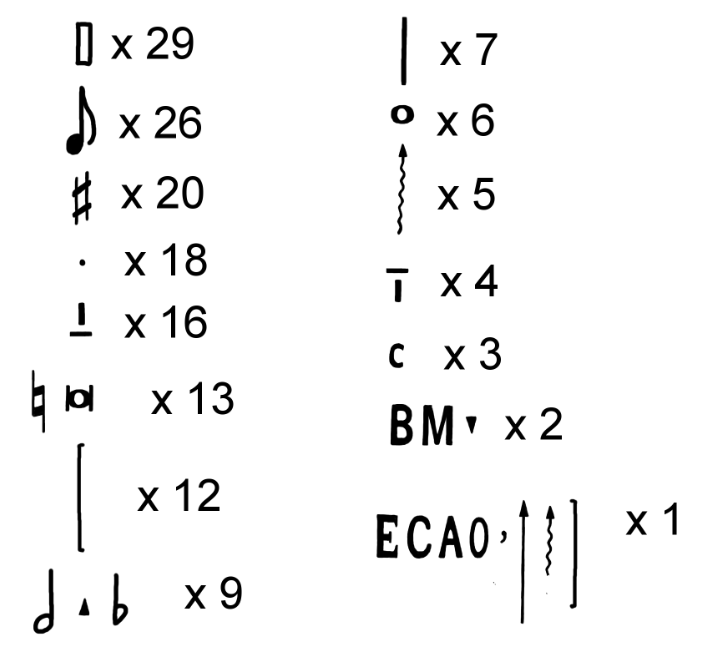
- アルファベットの数: 音楽記号22文字とA, B, C, E, M(5文字)の計27文字。A, B, C, E, Mを暗号化が外された文字と見るならば計22文字。
- 文字の出現頻度: 前記事の図を再掲(図1)。□, ♪の頻度が突出して高い。
- 語尾の文字: 言語によって、語尾に来やすい文字に特徴がある。暗号を右から読むか、左から読むかは分からないため、暗号文の元画像における2文字以上の単語の左端の文字(青)と右端の文字(赤)をピックアップした(図2)。原文を左から右に読む場合、□が語尾に来る頻度が突出して高く、逆方向に読むならば、♪ ♯ . が語尾に来る頻度が高い。(図3)
- 単語の文字数で色分けする(図4)。少数文字(2文字, 3文字)の単語はパターンが少ないため、各言語の前置詞や接続詞などの頻出単語と比較すると当たりをつけることができるかもしれない。
- 一文字の単語: 文中では □, ↑, ♭, ♯ が一文字で出現する。特に □ は3回も出てくる。(図4)



以上の手掛かりを元に、各言語の考察へと進んでいく。
1.日本語(ローマ字)
- アルファベット: 母音5文字+子音14文字(K,S,T,N,H,M,Y,R,W,G,Z,D,B,P)の19文字。音楽記号22文字だけだとしても3文字余ることになる。
- ローマ字は、子音と母音が必ずセットになるため、以下の制約がある。
(1)語尾は、母音またはNでなければならない。
(2)異なる種類の子音は2つ以上続いてはいけない。(例外1:K, S, T, N, H, M, R, G, D, B, Pの後ろにYが続く場合。例外2:Nの後ろに子音が続く場合)
(3)同じ種類の子音は3つ以上続いてはいけない → 暗号に3つ以上同じ文字が続いてところはないのでOK. - 上項の(1)を満たすためには、右端、もしくは左端の文字が6種類(母音+N)以下でなくてはならないが、アルファベットを除いても、それぞれ15, 12種類ある(図3)。どう割り振っても(1)を満たすことができない。このことから、ローマ字の線は薄そうである。
まとめ
- ローマ字を表すのに必要な文字数が少ないため、暗号の文字が余る
- 語尾の文字の種類の数を考えるとローマ字の線は薄そう
2.英語
- 文字: アルファベット26文字。暗号の文字の種類とかなり近い数である。
- 一文字で成立する単語: “I”(私は)と “a”(不定冠詞)が候補となる。試しに、□ = “i”, “a” と置いてみる。どちらの場合も、元の暗号文を左から右に読むことになる。
- 語尾: 英語の語尾の頻出文字の候補に、”e” や ”s” がある。“e”は、名詞・動詞・形容詞にかかわらず、”*a*e” (make, take, late, name, save...) や、”*i*e” (like, time, nice...)の形の単語が多い。”s” は複数形、三人称単数などで使われる。ただし、読む方向が左から右である場合、□が語尾にくる回数が多いので □ = “e”, “s” となり、前項と整合しない。
以下に、汎用かつ頻出と思われる単語をリストアップする。
- 冠詞: a, an, the
- 前置詞: at, by, in, of, on, to, for, with, fromなど
- 人称代名詞: I, he, my, me, her, his, him, she, you, they, them, their など
- be動詞: am, be, is, are, was, were
- 助動詞: can, may, will, must, shall, should など
- 指示詞: here, that, this, there, these, those
- 接続詞: as, if, or, so, and, but, yet, until, while など
- 疑問詞: how, who, why, what, when, where, whose
- その他: no, not, do, than
リストを眺めていると、暗号文における2文字の単語の出現頻度がやや少ないことが気になった。暗号の中には2文字の単語が3種類しか出てこない。参考までに「望郷の歌」の英語の歌詞は、冒頭4行だけでan, be, do, in, is, my, no, of の8種類が出てくる。英語ならばもっと2文字の単語がでてきても良い気がする。
まとめ
- アルファベットの数はかなり近い
- 一文字の単語の候補: “i”, “a”
- 読む方向: 左から右
- 語尾に頻出の文字の候補:”e”, “s”
- 2文字の単語の出現頻度が少ない(?)
3.フランス語
- 文字: ラテンアルファベット26文字 + アクセント3種(´ ` ^)、トレマ(¨)、セディーユ(ç)、合字(œ)を含む特殊文字15文字
- 特殊文字について:
(a) 全て書き下すと15文字(é, à, è, ù, â, ê, î, ô, û, ë, ï, ü, ç, œ, æ)
(b) アクセント変換表を用いて分解すれば6種類(' ` ^ : , &) - (a)の場合計41文字、(b)の場合でも計32文字と多い。また、(b) の場合は、暗号の文字2つで特殊文字1つに対応する(例:â → a^)ため、文字数の判定がややこしくなる。
- 一文字の単語: 場所を表す前置詞 “à” が文頭に来て大文字になるときはアクセントを省略することが多いらしいので、"a", “à” が候補となる。□ = "a", “à”と置いてみると、原文は英語と同じく左から右に読むことになる。もう一つの候補として、”Il y a ~”(~がある)の"y"を考えたが、"y"は必ず”a”とセットで使うため一文字の単語が連続する形になり、そのようなものは暗号文の中にないため除外。
- 語尾: フランス語の語尾に来やすいものは、子音だと”s”, “t”、母音だと”e”である。ただし、英語で議論したときと同じように、□ = ”e”, ”s”, “t” とすると前項と整合しない。
頻出単語リスト
- 冠詞: du, de, le, la, un, les, des, une
- 前置詞: à, en, de, par, sur, avec, dans, pour など
- 人称代名詞: il, je, la, le, me, te, tu, eux, ils, les, lui, moi, toi, elle, leur, nous, vous, elles など
- be動詞: es, est, etes, etre, sont, suis, sommes など
- 助動詞: être, avoir など
- 指示形容詞、指示代名詞: ce, ces, cette, celui など
- 接続詞: et, or, ou, car, donc, mais など
- 疑問詞: où, qui, que, dont, quoi, lequel
- 否定: ne, pasなど
(英語と同じく、暗号文における2文字の単語の出現頻度がやや少ない気がする。)
まとめ
- 特殊文字を含めると文字数が多い(特殊文字の表し方が複数あり、ややこしい)
- 一文字の単語の候補: "a", “à”
- 読む方向: 左から右
- 語尾に再頻出の文字の候補:”e”, ”s”, “t”
- 2文字の単語の出現頻度が少ない(?)
4.エスペラント語
- ハオルシアの世界観との相性: ハオルシアの物語に特定の国の言語は出てこない。国は大陸単位で統一され、国連がそれらを取りまとめている。このことから、世界共通言語を目指して作られたエスペラント語は、ハオルシアの世界観と相性が良いと感じられる。あくまで直感なのだが、このような "必然性" を感じられる言語は有力な候補である。
- 文字: 英語のアルファベットからq, w, x, yの4文字を抜き、ĉ, ĝ, ĥ, ĵ, ŝ, ŭの6文字を加えた計28文字。ごく少数の語にしか使われない ĥ を除けば、27文字で暗号の文字数と一致する。
- 一文字の単語: エスペラント語の問題は「一文字の単語」がない(?)ことである。少なくとも筆者が探した限りでは、候補となりそうなものは見つからなかった。
- 語尾のルールが以下のように統一されている。
- 名詞: -o (複数形 -oj) → 目的格 -on, -ojn
- 形容詞: -a (複数形 -aj)
- 副詞: -e
- 動詞:現在形 -as, 過去形 -is, 未来形 -os
頻出単語リスト
- 冠詞: la(定冠詞のみ)
- 前置詞: al, ĉe, da, de, el, en, je, po, dum, kun, laŭ, per, por, pri, tra など
- 人称代名詞: ĝi, li, mi, ni, si, ŝi, vi, ili, oni(対格は -n, 所有格は -a)
- be動詞: esti, estas, estis, estos, estu, estus
- 助動詞: povi, devi, rajti など
- 指示詞: tio, tiu, ĉi tio, ĉi tiu など
- 接続詞: aŭ, ĉu, ke, ol, se, ĉar, dum, ĝis, kaj, nekなど
- 疑問詞: kio, kiu, kia, kies, kie, kiel, kial, kiam, kiom
- その他: 否定文 ne~pas, 接尾辞 mal- で意味が反対になる
(英語、フランス語と同じく、暗号文における2文字の単語の出現頻度がやや少ない気がする。)
まとめ
- ハオルシアの世界観と相性が良い
- 文字の種類の数はほぼぴったり合う
- 一文字の単語に当てはまるものがない(?)
- 語尾に頻度の文字の候補を絞りにくい: ”a”, ”e”, “i”, ”o”, ”n”, ”s”, "l", “j” など
- 2文字の単語の出現頻度が少ない(?)
5.サンスクリット語
- 文字: デーヴァナーガリー文字のローマ字表記。
- 母音13種類: a, ā, i, ī, u, ū, ṛ, ṝ, ḷ, e, ai, o, au
- 子音35種類: k, kh, g, gh, ṅ, c, ch, j, jh, ñ, ṭ, ṭh, ḍ, ḍh, ṇ, t, th, d, dh, n, p, ph, b, bh, m, y, r, l, v, ś, ṣ, s, h, ḥ, ṃ
- 文字としては以下の36文字。結構多い。
a, ā, i, ī, u, ū, ṛ, ṝ, ḷ, e, o, k, g, ṅ, c, j, ñ, ṭ, ḍ, ṇ, t, d, n, p, b, m, y, r, l, v, ś, ṣ, s, h, ḥ, ṃ
- 一文字の単語: エスペラント語と同じく、ローマ字表記で一文字の単語を見つけることはできなかった。
- 頻出文字: 文字の中では “a” の出現率がダントツで高い。次いで “ā” も良く出現する。出現頻度(図1)を参考にすると、□ = “a”, ♪ = “ā” となる。
- 名詞:3つの性、3つの数、8つの格がある。全てをリストアップすると膨大になるので、ここでは雰囲気をつかむため一部のみ示しておく。
- 第一人称の人称代名詞(単数): aham, mām (mā), mayā, mahyam (me), mat, mama (me), mayi
- 第二人称の人称代名詞(単数): tvam, tvām (tvā), tvayā, tubhyam (te), tvat, tava (te), tvayi
- 指示代名詞「tad:それ、これ」(男性・単数): saḥ, tam, tena, tasmai, tasmāt, tasya, tasmin
- 関係代名詞「yad-:”who”, “which”」(男性・単数):yaḥ, yam, yena, yasmai, yasmāt, yasya, yasmin
- 動詞: 文中では「接頭辞+語幹+人称語尾」の形で現れる。
- 語尾の文字: 子音が語尾にくることが多く、突出して頻度が多い文字はなさそうである。
- (以下、ハオルシア本編のネタバレを含むので反転)
古代語が使われる意味: ハオルシアでは、物語の最後に「主人公たちが去っていった星は、シアノバクテリアが生まれる前の地球だった」ということが明かされる。SFだと思っていた物語の舞台は、実は太古の地球だったのである。そのことを思えば、"古代語" が暗号として採用されることに意味を見出すことができる(実際の舞台はサンスクリット語が登場するずっとずっと前ではあるのだが。)
まとめ
- アルファベットの数が多い(ローマ字表記で最低36文字)
- 再頻出の母音の候補: ”a”, “ā”
- 一文字の単語に当てはまるものがない(?)
- ハオルシアの世界観と相性が良いかも(?)
以上、5言語について検証してみた。所感としては、ぴったり当てはまる言語は、今のところなさそうであった。特に “□” の制約が厳しく、以下の3つの条件を全て満たす言語は今のところなさそうである。
- □が一文字の単語として存在
- □の出現頻度が最も多い
- 単語の右端に□が出現する頻度が最も多い(逆に、左側に出現する頻度は少ない)
無理やり解釈する方法として、「□は句点・イニシャルを表す」「□はダミーである」「一文字の□を隣の単語とつなげる」などの手はあるが、それらを検討するのは最終手段に取っておきたい。次は、もう少し他の言語にも可能性を広げてみることにする。